
開発時期:2023年
開発者:AmpiTa Project
開発言語:C#言語(Visual Studio 2022)
目次
- 背景・概要
- 開発作業
- 邪魔にならない開始位置
- デザインを邪魔しないコンボボックス
- Textbox都度チェック
- 全角⇒半角、カナ抜き
- ファイル操作
- Schema毎回更新
- DataGridViewの現在地
- ExcelDataReader
- 無限ループ『While』
- URL生成にIndexOf
- 年度の計算
- お決まりのパターンボタン
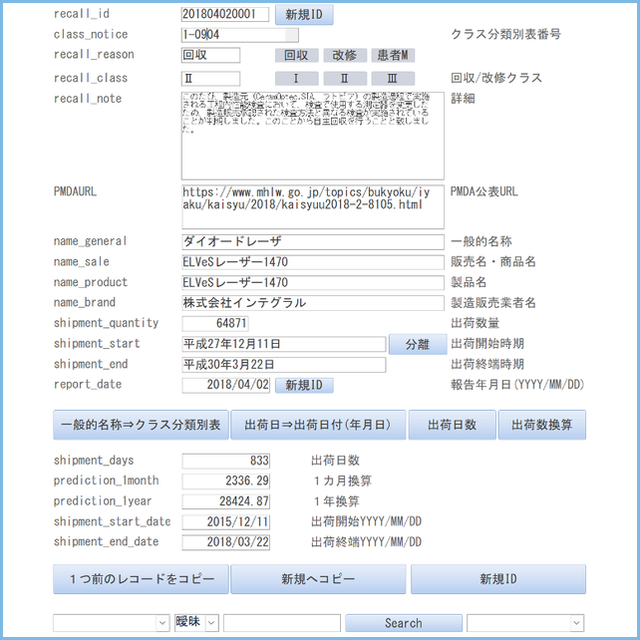
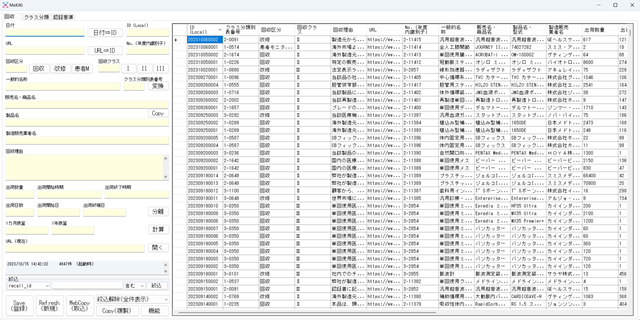
- 操作手順[回収情報入力]
- 操作手順[CSVエクスポート]
- 操作手順[ウェブデータベース]
- 操作手順[月間レポート]
- 操作手順[ユニーク数]
- おわりに
背景・概要
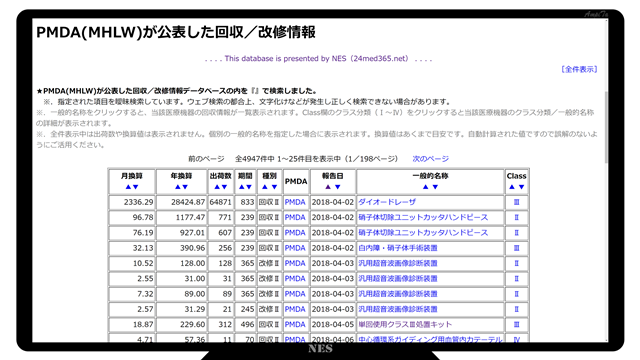
医療機器の不具合等に関する回収や改修の情報は2018年までさかのぼることができます。それ以前のデータはインターネット上には公表されていません。
2018年までさかのぼれるとしても、それはデータベース化されている訳ではなく、ウェブサイトに公開されているにすぎず、その公開方法は1案件1ページのウェブページを持っているので、5,000件あれば5,000ページに分散しています。
さらに、当初3年間はPMDA(医薬品医療機器総合機構)が公表し、それ以降は厚生労働省のウェブサイトに移されます。
不具合に関する情報はメーリングリストで受け取るのですが、そこに記載されているURLは最長3年間有効、それ以降はUnknownなURLとなってしまいます。
他方、医療機関では当該医療機器を10年後でも使用しつづけるので、過去の不具合が振り返れないのは困ります。
そこで、過去データも包括して管理できるシステムを構築しようと2022年にMicrosoft Accessを用い、AccessVBで制御を加えたデータベースを構築しました。
情報を残すということについては問題ないデータベースでしたが、入力項目の多さから手間がありました。
ウェブページから省力的にデータを取得したいと考え、コピペ機能を追加しようと考えた時、AccessではやりづらさがあったためC#(Visual Studio)を使った新たなシステム開発に踏み切りました。
医療機器の回収/改修情報には厚生労働省が定める一般的名称が使われるため、そのデータベースとの連携も必要です。これは毎月更新され、Excelでダウンロードできます。
このデータベースも内包する必要があります。
医療機器の中には認証基準を持つものがあります。これは機器開発において必要になるので、医療機器開発に携わる人には有用な情報です。今回はこれもデータベース化して付加しています。
これら3つのデータベースは、MeKiKi.meのウェブサイトで公開されています。
開発作業
作業1.基本設定(環境設定)
Visual Studio 2022を使ってC#のシステムを開発する最初の手順は環境設定です。
そもそも、C#を使うということも基本的な環境設定の1つです。
まず、保存先となるフォルダを作ります。
Visual Studio 2022を起動し、.NetFrameworkでアプリを制作する設定をしていきます。
アプリの名称、64bit設定、リビジョン番号など気づいたものを設定しました。
作業2.デザイン・基本構想
『デザイン』とは、見た目に関わる意匠的なデザインと、仕組みに関わる設計的なデザインがあります。
自身で企画も開発も行う場合、すべてのデザインは自身に委ねられます。
作業3.データベース基本設計
今回はデータベースに連動するシステムであり、国の機関から公表されているデータをまとめることになるので、データ項目が既定されています。
まずはExcelでも何でも良いので、既定項目で表をつくります。
その後、自身のデータベースに必要と思われる項目を付加していきます。
ユニークなIDは必須です。
登録日や更新日、作業者を記録するデータベースは多いです。
今回は出荷期間と出荷数量から、平均出荷量を導き出して表示する項目を追加しています。
参照先があるので必須項目が既定されていますが、その内容は一定ではなく、多くの調整を要する帳票になりそうなので、あとで多くの変更が生じないように基本

作業4.フォーム基本設計
フォームは作業効率にも関わるので入念に検討します。
眺めていてもわからないので、とりあえず配置して動かしながら、入力しやすさを追求していきます。
『基本設計』としているのは、このあと『実施設計』に移るための前処理であるためです。
タブが移動する順番も重要ですし、Enterキーで何かの処理が自動的に行われるようにしたり、2つのデータを対比しながら作業を進めやすくしたり、細かな調整が待っています。
作業5.制作(PDCA)
ここから先は、何度も壊して直すようなPDCAサイクルの始まりです。
作業記録
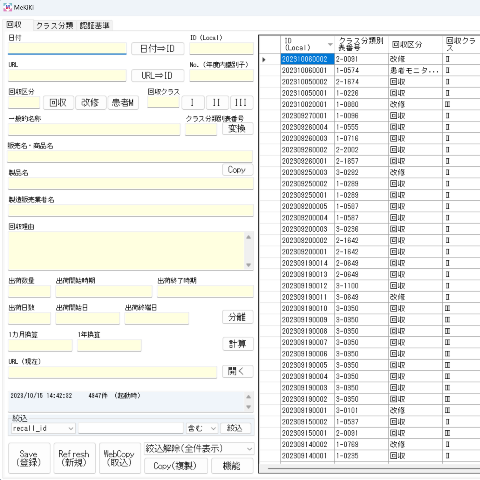
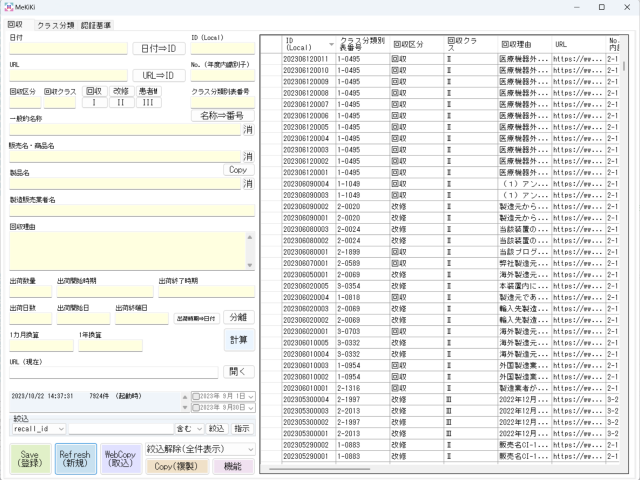
邪魔にならない開始位置
このシステムで扱うデータは、回収情報に関しては週3回程度の発出がありますが、クラス分類表は月1回程度、認証基準情報は年に数回程度の発出です。
出先で扱う必要がないため、画面サイズは職場のディスプレイとして使っている3840×2160を基準に考えました。
一方で、何らかの都合でノートパソコンで処理することもあるだろうと考え、1920×1080でも対応可能としました。
その結果、フォームのサイズは1800×900としました。
フォームを中央に表示させれば作業がしやすいように思いましたが、今回はウェブページを皆がらの入力作業が想定されることから、ウェブページと並べて作業しやすい位置を検討しました。
結論としては、普段ウェブブラウザを画面の右側に寄せて利用していることから、フォームは左に寄せるのが良いと考えました。
これは一人用、自身専用であるから良い位置であって、万人受けする位置は不明です。
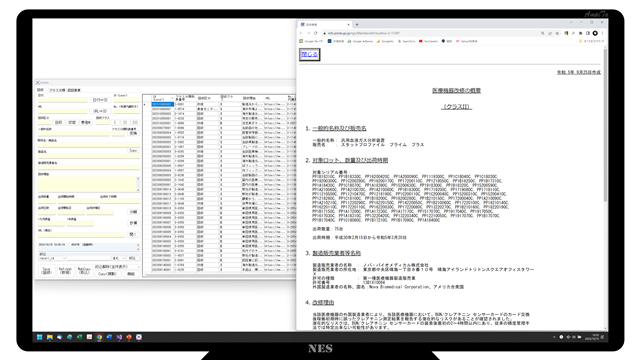
フォームを開いた状態でブラウザを開くと、ブラウザがフォームの手前に来るので問題なかったのですが、データ入力しようとフォームをクリックすると、肝心のブラウザの情報が見えないことがわかりました。
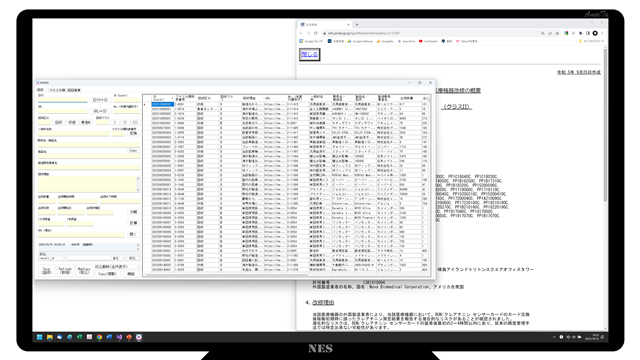
試行錯誤した結果、とりあえずフォームのサイズを900×900にすることで落ち着きました。
起動時は1800×900で横長、データベースは1つでも多くのセルを見れるようにしました。
作業時は任意で900×900まで小さくして入力しながらブラウザを確認できるようにしました。
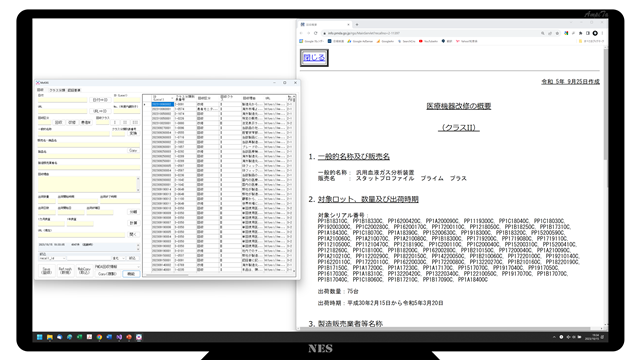
試行錯誤した結果、とりあえずフォームのサイズを900×900にすることで落ち着きました。フォームプロパティの MinimumSizeを設定しました。
フォームの起動時の位置は Location を使って設定しています。
X軸方向は 0 として画面左端へ、Y軸方向は画面サイズを取得した上で、その中心位置となる半数を算出します。これで中心線が決まります。
フォームの高さ(Height)は900なので、中心線は450の位置にあり、中心線より450高い位置、すなわち450少ない位置がフォームの上端(Top)となります。
これらの下記コードで表現してY軸位置を決定しています。
int int_Display_H = System.Windows.Forms.Screen.PrimaryScreen.Bounds.Height;
this.StartPosition = FormStartPosition.Manual;
this.Location = new Point(0, int_Display_H / 2 - 450);【参考】dobon.net:ディスプレイの大きさ(画面の領域、解像度)を取得する
【参考】dobon.net:フォームにスクロールバーをつける
【参考】@IT:Windowsフォームの開始表示位置を設定するには?
デザインを邪魔しないコンボボックス
全体のバランスがあるので、一部分だけ大きく幅をとることはできません。
下図の例ですと、絞込機能を1行で収める必要がありました。
絞込には項目名を選択するコンボボックス(ドロップダウン)、検索ワードを入れるテキストボックス、検索方法を一致や曖昧など選択するコンボボックス(ドロップダウン)、実行ボタンの4つは必要です。
コンボボックス(ドロップダウン)が狭いと項目名が表示しきれないという問題があったので、ボタンを押されるとリストは広く表示されるといった機能を備えました。
『for』でコンボボックスの Items を全部巡る指示を出します。
その Items のチェック時にバイト数を引出します。
バイト数の最大値を『Math.Max)で取得、最大値にコンボボックスのフォントサイズ(Font.Size)を掛けて割り出された数値をコンボボックスの幅としました。
フォントサイズによっては大きすぎることがあるので、その場合は適当な数字を掛けて小さくします。
経験的には8掛けくらいがちょうど良い気がします。
今回のコンボボックスはドロップダウンリストとして使うのでスタイル設定(DropDownStyle )を『DropDownList』にしておきます。
for (i= 0; i< cmb_Search.Items.Count; i++)
{
int_Max = Math.Max(int_Max, byte_Shift_JIS.GetByteCount(cmb_Search.Items[i].ToString()));
}
cmb_Search.DropDownWidth = (int)Math.Ceiling(cmb_Search.Font.Size * int_Max);
cmb_Search.SelectedIndex = 0;
cmb_Search.DropDownStyle = ComboBoxStyle.DropDownList;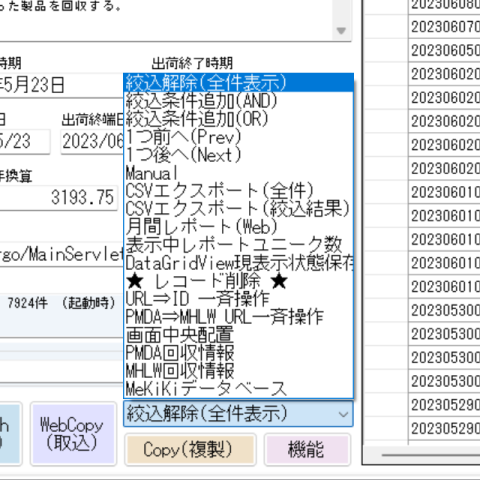
Textbox都度チェック
基本的にはデータを転記して登録するシステムなので、データ入力が重要です。
各項目で文字、数字、日付など書式が異なるので、それらが適正であるかを確認する必要があります。
そもそも、入力忘れは問題ですので、空欄のテキストボックスは色を変えてあります。
private void Textbox_Refresh()
{
txb_report_date.Text = string.Empty; txb_report_date.BackColor = Color.LightYellow;
txb_recall_id.Text = string.Empty; txb_recall_id.BackColor = Color.LightYellow;
}テキストボックスには『Leave』の設定を仕込んでおき、離れるときに空欄なら色付き、そうでなければ白色に背景色(BackColor)を変える設定を施しています。
private void txb_Recall_URL_No_Leave(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(txb_Recall_URL_No.Text))
{ txb_Recall_URL_No.BackColor = Color.LightYellow; }
else
{ txb_Recall_URL_No.Text = txb_Recall_URL_No.Text.Trim(); txb_Recall_URL_No.BackColor = Color.White; }
}全角⇒半角、カナ抜き
全角を半角にするコードに下記があります。
str_Temp = Microsoft.VisualBasic.Strings.StrConv(str_Temp, Microsoft.VisualBasic.VbStrConv.Narrow, 0x411); ただし、これを使うとカタカナも半角になってしまうので、思わぬ表示不具合が発生します。
そこで今回は『Dictionary』を使って指定した文字だけを全角から半角に置き換えるプログラムを作りました。
まず、辞書を作ります。この辞書が間違えていたら終わりです。
var var_Conversion_Character = new Dictionary<char, char>()
{
{'1','1'},{'2','2'},{'3','3'},{'4','4'},{'5','5'},
{'6','6'},{'7','7'},{'8','8'},{'9','9'},{'0','0'},
{'A','A'},{'B','B'},{'C','C'},{'D','D'},{'E','E'},
{'F','F'},{'G','G'},{'H','H'},{'I','I'},{'J','J'},
{'K','K'},{'L','L'},{'M','M'},{'N','N'},{'O','O'},
{'P','P'},{'Q','Q'},{'R','R'},{'S','S'},{'T','T'},
{'U','U'},{'V','V'},{'W','W'},{'X','X'},{'Y','Y'},
{'Z','Z'},
{'a','a'},{'b','b'},{'c','c'},{'d','d'},{'e','e'},
{'f','f'},{'g','g'},{'h','h'},{'i','i'},{'j','j'},
{'k','k'},{'l','l'},{'m','m'},{'n','n'},{'o','o'},
{'p','p'},{'q','q'},{'r','r'},{'s','s'},{'t','t'},
{'u','u'},{'v','v'},{'w','w'},{'x','x'},{'y','y'},
{'z','z'},
{'(','('},{')',')'},{'[','['},{']',']'},{'-','-'},
{'/','/'},{' ',' '}
};次に、辞書のキー文字に一致する文字(Character)は無いか確認し、見つかれば置き換えます。
str_Conversion = new string(str_Conversion.Select(n => (var_Conversion_Character.ContainsKey(n) ? var_Conversion_Character[n] : n)).ToArray());これを実行することでカタカナが半角化されてしまう課題から解放されました。
ファイル操作
フォーム起動時には下記コードを実行して自動的にDataGridViewへデータベースを接続し、表示しています。
if (System.IO.File.Exists(strPath_XML_File) && System.IO.File.Exists(strPath_Schema_File))
{
dt_Recall = new DataTable();
dt_Recall.TableName = "dt_Recall";
dt_Recall.ReadXmlSchema(strPath_XML_File);
dt_Recall.ReadXml(strPath_Schema_File;)
dataGridView1.DataSource = dt_Recall;
}冒頭で行う『File.Exists』はエラー回避に欠かせない処理です。
前述のXMLファイルの呼出では、もしファイルが存在しなければ処理は行わないでスキップするだけでした。
下記コードでもXMLファイルが存在しない場合の処理は同じですが、その手前にあるバックアップフォルダ(ディレクトリ)の存在確認の際には、存在しなかった場合に『Directory.CreateDirectory』を使って当該名称のフォルダ(ディレクトリ)を創成しています。
if (System.IO.File.Exists(strPath_BackUp))
{ }
else
{
Directory.CreateDirectory(strPath_BackUp);
}
if (System.IO.File.Exists(strPath_XML_File)
{
System.IO.File.Copy(strPath_XML_File, strPath_BackUp + "\\" + "recall_Pre.xml", true);
}このファイルの存在確認についてはExcelやCSVファイルでも使えるので、多用しています。
上記コードにある『System.IO.File.Copy』ですが、これはファイルをコピーすることができる命令です。
ここでは、XMLファイルのバックアップ用に使っています。コードはフォーム起動(Load)と終了(Closing)の2回実行されます。起動時は『Pre』、終了時は『Post』という文字をファイル名に記載しています。
他に『System.IO.File.Delete』を使ったファイルの削除、『System.IO.File.Move』を使ったファイルの移動、『System.IO.File.Open』を使ったファイルを開く処理などを行っています。
System.IO.File.Delete(strPath_BackUp);System.IO.File.Move(strPath_XML_File, strPath_BackUp + "\\" + "ME_Class.xml"); System.IO.File.Open(@Load_File_Path, FileMode.Open, FileAccess.Read)【参考】dobon.net:ファイル、ディレクトリが存在するか調べる
【参考】@IT:ディレクトリを作成/削除/リネーム/移動するには?
【参考】@IT:ファイルをコピー/削除/リネーム/移動するには?
Schema毎回更新
必要性があるかどうかわかりませんが、XMLのSchema(.xsd)は起動毎に書き換えています。
テーブル名(TableName)は共通でないとXMLファイルとの不整合が発生しますが、それ以外は多少の調整は可能なので、常に最新であるように更新しています。
メリットとしては、XSDファイルを探すコードを省けること、探してエラーがあればXSDファイルを作ることになるので、それであれば最初から作ってしまえば良いかなという考えです。
古いXMLファイルを持ち込んで読込んだ場合、当時は無かった項目名も自動的に追加されるので、最新化が容易になります。
当時無かった項目については、XMLファイル内には項目名が無いままなので、データを入れない限りは何も変わりません。
追加された項目のデータを入力して保存すれば、その項目が追加されていくので、処理としては難しくありません。
DataGridViewの現在地
以前からDataGridViewは多用していたので、今回も例にもれず使用します。
あまり細かな設定は行っていません。
DataGridViewの最後に空白の1行が見えているのが紛らわしいため『AllowUserToAddRows 』で見えないように設定しています。
データが1つでもあれば『Rows.Count』が1行以上、すなわち0を超過するので『dataGridView1.Rows.Count > 0』で判断しています。
もし true であった場合『Columns[0]』、すなわち1番左にある列を基準に並べ替えする指示『ListSortDirection』を出しています。この例では『Descending』なので値の大きい方から小さい方へ行く降順です。逆順である『Ascending』も使用しています。
dataGridView1.DataSource = dt_Recall;
dataGridView1.AllowUserToAddRows = false;
if (dataGridView1.Rows.Count > 0)
{
dataGridView1.Sort(dataGridView1.Columns[0], System.ComponentModel.ListSortDirection.Descending);
dataGridView1.CurrentCell = dataGridView1[0, 0];
}その下の『CurrentCell』は『0,0』なので先頭行の先頭列を選択状態にするよう指示しています。
『dataGridView1.CurrentCell』で能動的にセルを指定することはできましたが、現在選択中のセルや行を明らかにする方法が必要になりました。
レコードの削除機能を作るのが面倒であったので、DataGridViewで選択中のレコードを削除できれば良いなと考えました。
下記コードは現在選択中のレコードを削除する指示をするボタン押下か何かのトリガが発生したあとの処理です。
最初にYesNoの選択で行を削除するか否かを聴いています。
ここで『CurrentRow.Cells[0].Value』が現在の行(Row)における列番号ゼロを示す『Cells[0]』、そのセルの値(Value)を示すように指示しています。
ヘッダー文字を引用する『Columns[10].HeaderText』はどの行を選択しているか関係ないので『Columns[10]』がわかれば十分です。
選択ボタンで Yes が選ばれた場合、処理として『Rows.Remove』が実行され、対象の行(Row)は削除されます。
その行の指定に『CurrentRow』を使っています。
DialogResult diares_Result = MessageBox.Show(
"選択中の行を削除します。" + "\r\n" +
dataGridView1.CurrentRow.Cells[0].Value + "\r\n" +
dataGridView1.Columns[10].HeaderText + "\t" +
dataGridView1.CurrentRow.Cells[10].Value,"削除", MessageBoxButtons.YesNo);
if (diares_Result == DialogResult.Yes)
{
dataGridView1.Rows.Remove(dataGridView1.CurrentRow);
}【参考】dobon.net:DataGridViewの現在のセルを取得、または変更する
ExcelDataReader
医療機器のクラス分類表はPMDAからExcelファイルとPDFファイルで提供されています。
Excelがあるのは良いのですが、拡張子は『.xls』です。
昔のMicrosoft Excel 97の時代から使われている拡張子なので古いです。ちょっとした不都合があります。
これまでに開発したソフトウェアでも利用してきた『ExcelDataReader』という便利ツールは、残念ながら『.xls』は非対応です。
今回のシステムは自身の業務負荷軽減を目的としているためユーザーは1人、仕方ないのでPMDAから貰うExcelファイルを毎回、Excelを使って『.xls』から『.xlsx』に保存し直すこととしてプログラミングしました。
冒頭の using で読込むファイルを指定、次の行で読込んだExcelファイルを扱う名称を定義しています。
最初の作業は、目的のシートを探す処理です。
今回は『一般的名称等一覧』というシートを探します。PMDAが勝手に名前を変えないことを願っています。
この名称のシートを見つけるまで for で巡り、見つからなかったら処理をやめます。
using(FileStreamstream=System.IO.File.Open(@Load_File_Path,FileMode.Open,FileAccess.Read))
using(IExcelDataReaderexcelReader=ExcelReaderFactory.CreateOpenXmlReader(stream))
{
for(int_Excel_Sheet=0; int_Excel_Sheet<excelReader.ResultsCount; int_Excel_Sheet++)
{
if (excelReader.Name!="一般的名称等一覧")
{excelReader.NextResult();}
else
{break;}
}
if (excelReader.Name!="一般的名称等一覧")
{
MessageBox.Show(" 目的のSheetが見つかりませんでした。","処理中止");
}Excelデータ(Sheet)をデータセット(DataSet)として扱う設定をします。
並行して既存のXMLをバックアップに回します。これまで使用中であったXMLファイルをそのままバックアップフォルダに移動(Move)させる指示を出しています。
このあと、Excelファイルが取り込まれればXMLファイルは新設されるので、古いファイルは必要なくなるため、とりあえず移動させています。
var ds_Data_Set_Excel = excelReader.AsDataSet();
if(System.IO.File.Exists(strPath_XML_File))
{
dataGridView2.DataSource=null;
System.IO.File.Move(strPath_XML_File, strPath_BackUp + "\\" + "Before_ME_Class.xml");
}
dt_ME_Class = newDataTable();
dt_ME_Class.TableName = "dt_ME_Class";
dt_ME_Class.ReadXmlSchema(strPath_XML_File); Excelの行数を取得しています。
この行数分だけ While を回します。Forで回すのとどちらが効率的かわかりません。結局は int 関数の足し算(i++)を毎回実行し、基準値との比較(i < intRowCount)を周回毎に毎回実施しているので処理としては While も For もよく似ています。
Excelからデータを読込む処理は『Rows[i][intC].』で行っています。 i 行目にある intC 列目のセルにある情報を、仮設しているデータセットの intC 列目『dt_Temp_Row [intC]』に格納するという処理を行います。
このとき、文字列の中に半角カンマ(,)が含まれていると、あとでCSVファイル出力の際に困るので、カンマは句点に置き換える『Replace』処理を入れています。
仮設のデータテーブル『dt_Temp_Row 』のデータをメインのデータテーブルに『Rows.Add』で書き込めば、その1行の処理は完了です。
これを、While から抜けるまで延々と続けます。
int intRowCount = ds_Data_Set_Excel.Tables[int_Excel_Sheet].Rows.Count;
i = 2;
while(i < intRowCount)
{
DataRow dt_Temp_Row = dt_ME_Class.NewRow();
for(int intC = 0; intC < 21; intC++)
{
dt_Temp_Row [intC] = ds_Data_Set_Excel.Tables[int_Excel_Sheet].Rows[i][intC].ToString().Replace(",","、");
}
dt_ME_Class.Rows.Add(dt_Temp_Row );
i++;
}
dt_ME_Class.WriteXml(strPath_XML_ME_Class_XML_File);【参考】プロメモ:【C#】Excel ファイルの読み込みなら ExcelDataReader がおすすめ
【参考】ASPOSE:C#でExcelファイルを読み取る方法
無限ループ『While』
データベースは識別用にユニークなキーを設けることが一般的です。
当データベースでもユニークIDをローカルで指定しています。
回収等の情報は日付を基にして、たとえは2023年11月1日であれば『20231101』を頭に付けます。取得方法は下記のとおりです。
str_report_date = datetimeCheck.ToString("yyyyMMdd");次に、この8ケタの年月日の後ろに4桁の数字を入れます。
回収情報が1日に1万件も出ないだろうと考えての4桁ですが、別なプログラムでは5桁にしたり、16進数にしたり、色々と工夫しています。
4桁にする方法は『int_ID.ToString(“D4”)』です。この『D4』はゼロ詰めで4桁にしなさいというものです。
似たもので『F4』がありますが、こちらは小数点以下第4位まで表示するという指示です。整数型の int では使いませんが、今回のプログラムでは double の所で使っています。
4桁であれば0~9,999なので、ForでもWhileでも9999以下で処理しなさいという『i < 10000』というのをよく使っていましたが、今回は無限ループを使いました。
無限ループは『while (true)』の記述です。この『true』を書くと無限に回ります。
while (true)
{
int_ID++;
str_ID = str_report_date + int_ID.ToString("D4");
if (dt_Recall.Select("recall_id ='" + str_ID + "'").Count() == 0
{
txb_recall_id.Text = str_ID.ToString();
return;
}
}【参考】websandbag ブログ:【C#】無限ループの書き方色々
URL生成にIndexOf
医療機器の回収・改修情報の公表元はPMDA(医薬品医療機器総合機構)です。
回収等の情報が出ると下記のようなURLで公表されます。
https://www.info.pmda.go.jp/rgo/MainServlet?recallno=2-11405上記アドレスの末尾『2-11405』はクラスIIの11405番の回収等の情報であることを示しています。
PMDAは独立行政法人であり、医療機器等の回収などの情報管理は国からの委託(?)業務として行っています。
委託期間が3年なのかわかりませんが、直近3年度分はPMDAのウェブサイトで閲覧、それ以外は厚生労働省のウェブサイトに移ります。
従って、URLが3年度後には変更されてしまいます。さきほどの『2-11405』は下記のURLになります。
https://www.mhlw.go.jp/topics/bukyoku/iyaku/kaisyu/2023/kaisyuu2023-2-11405.htmlそこで、PMDAのURLをMHLWのURLに変換するプログラムを作りました。
まずPMDAのURLを参照します。そのURLがPMDAのものであるかを確認するための『str_URL.Contains(“pmda”)』と、IDが含まれるURLであるかを確認する『str_URL.Contains(“recallno=”)』をIf文で判定します。
foreach (DataRow dtRow in dt_Recall.Rows)
{
string str_URL = dtRow["PMDAURL"].ToString(); Console.WriteLine(str_URL);
int int_StringLength;
if (str_URL.Contains("pmda") && str_URL.Contains("recallno="))
{
int_StringLength = str_URL.IndexOf("recallno=") + 9;
}
else if (str_URL.Contains("mhlw") && str_URL.Contains("kaisyuu2"))
{
str_URL = str_URL.Replace(".html", "");
int_StringLength = str_URL.IndexOf("kaisyuu2") + 12;
}
else { continue; }
dtRow["recall_no"] = str_URL.Substring(int_StringLength).ToString();
} その上で『str_URL.IndexOf(“recallno=”)』の文字をURLの中から探し、発見した位置をIndexOfから返してもらいます。
このままだとURLの中の『r』の位置を示しているだけなので、数字が始まる位置まで移動、ここでは『r』より9文字後なので『+9』を記述しています。
https://www.info.pmda.go.jp/rgo/MainServlet?recallno=2-11405PMDAのウェブサイトはPHPを使っているので『?』の後ろに識別用の記号として『recallno』と『2-11405』が入りましたが、厚生労働省のウェブサイトはHTMLなので、もうひと手間かかります。
『str_URL.Replace(“.html”, “”)』を使って『.html』を削除しています。
ここでは IndexOf と Contains と Replace を使ってURLから必要な部分を取り出しました。
【参考】dobon.net:文字列から指定した部分を取得する
【参考】dobon.net:文字列内に指定された文字列があるか調べ、その位置を知る
【参考】ITSakura:C# IndexOf 文字列の位置を取得する
年度の計算
前述のURLの書式設定においてもう1つの課題がありました。それは年度の計算です。
年度毎にウェブファイルがPMDAからMHLWへと移されるので、年度を計算して処理する必要があります。
まず、期限について現在時から3年度分までをPMDAとする処理をするため、3年度前の初日を算出するコードを描きました。
現在時(DateTime.Now)から西暦年(yyyy)を取得し、それを整数(int)として変数『int_YYYY』に代入しました。例えば 2023 という数字が入ります。
処理する日を基準にするので『DateTime.Now』で現在日時を呼出、『yyyy』で西暦年を取得、『Int32.Parse』で数値化し『int_YYYY』に代入しました。
まずはどの年度に属するのか確認したいので、西暦年と4月1日を組み合わせた日付(DateTime)を作ります。
その日付、例えば 2023/04/01 00:00:00 が作られた場合、その日付と現在時(DateTime.Now)を比較してどちらが多き化を評価します。値が小さければ2022年度、大きければ2023年度ということになります。
DateTime datetime_Fiscal_Year_0401;
DateTime datetime_Fiscal_Year_This_0401;
int int_YYYY = Int32.Parse(DateTime.Now.ToString("yyyy"));
if (DateTime.TryParse((int_YYYY) + "/04/01", out datetime_Fiscal_Year_This_0401))
{
if (DateTime.Now < datetime_Fiscal_Year_This_0401)
{
int_YYYY = int_YYYY - 3;
}
else
{
int_YYYY = int_YYYY - 2;
}
if (DateTime.TryParse((int_YYYY) + "/04/01", out datetime_Fiscal_Year_0401))
{ }途中のコードを省略してますが、年度の数字をURLに反映させる処理が発生する厚生労働省(MHLW)の処理コードを示します。
回収報告書に記載の作成日を『dtm_Date_Recall』という変数に入れておきます。『DateTime.TryParse』を使ってデータベースから引き出しておきます。
回収報告書作成日と、PMDAとMHLWの境界となる年度初(4月1日0時)を比較し、古い(小さい)と判断された場合にはMHLWとして処理します。
次に、回収報告書作成日が属する年度を割り出します。回収報告書作成日の西暦年(yyyy)を取り出して4月1日の日付を作り、その yyyy/04/01 と比較して回収報告書作成日が前か後かで年度を規定します。
前であった場合マイナス1(int_YYYY – 1)を実行します。
if (DateTime.TryParse(dtRow["report_date"].ToString(), out dtm_Date_Recall))
{}
if (dtm_Date_Recall < datetime_Fiscal_Year_0401)
{
if (DateTime.TryParse(dtm_Date_Recall .ToString("yyyy") + "/04/01", out datetime_Fiscal_Year_This_0401))
{
int_YYYY = Int32.Parse(dtm_Date_Recall .ToString("yyyy"));
if (dtm_Date_Recall < datetime_Fiscal_Year_This_0401)
{
int_YYYY = int_YYYY - 1;
}
dtRow["LINKURL"] =
"https://www.mhlw.go.jp/topics/bukyoku/iyaku/kaisyu/" + int_YYYY.ToString("D4") + "/kaisyuu" + int_YYYY.ToString("D4") + "-" + dtRow["recall_no"] + ".html";
}
}そのあとが少しわかりづらいのですが、MHLWのURLは下記の仕様になっているので、それに合わせます。
https://www.mhlw.go.jp/topics/bukyoku/iyaku/kaisyu/2023/kaisyuu2023-2-11405.html頭の『https://www.mhlw.go.jp』は規定通りです。そのあとも『/kaisyu/』までは年度を問わず共通します。
次が年度を西暦で示す数字が入るので、先ほど割り出した年度が役立ちます。
『int_YYYY.ToString(“D4”)』では年度の西暦年を、4桁の数字にしなさいという命令ですが、既に西暦で取得しているので4桁以外は考えられないので無駄な処理とも言えます。ゼロ詰めで4桁にする『D4』は無くても良い処理かもしれません。
そのあと『/kaisyuu』という文字が来て、再び西暦年を使います。
ここのアルファベットは末尾が uu ですが、その前に出て来た kaisyu は u が1つでした。回収は『kaishu』ではなく y を使った『kaisyu』である点も独特です。
最後は回収識別番号となる『2-11405』のような記号を入れ、『.html』を付けるとURLが完成します。
dtRow["LINKURL"] =
"https://www.mhlw.go.jp" +
"/topics/bukyoku/iyaku/kaisyu/" +
int_YYYY.ToString("D4") +
"/kaisyuu" +
int_YYYY.ToString("D4") +
"-" +
dtRow["recall_no"] +
".html";同様に、回収・改修等の報告書が作成された日を基準に、年度がどちらになるかを評価するコードを記述しています。
ここで1つ問題が生じたのは、報告書作成日は企業の基準であり、PMDAと厚労省は掲載年月日という独自の基準で運用していることがわかりました。
この『掲載年月日』は報告書のウェブページに記載がありません。これを拾う術が国民側にはないのです。
おそらく、行政側のデータベースには掲載日が記録されており、それを基準にデータの受け渡しがPMDAと厚生労働省の二者間で行われれば済んでしまうので、国民が関与できるところではありません。
DXと言われてデジタルデータを活用しようと動いていますが、こうした小さな課題があちらこちらにあります。
お決まりのパターンボタン
医療機器の回収には集める『回収』、修正する『改修』、観察する『患者モニタリング』があります。
事象の危険度によってクラスが3つに分かれています。
PMDAや厚生労働省のウェブサイトでは、クラス別にページが設けられていますので、クラスは確実に見分けられなければなりません。
これらの『回収』『改修』『患者モニタリング』『Ⅰ』『Ⅱ』『Ⅲ』は手入力にも対応しますが、原則としてボタンを押して入力する方法としました。
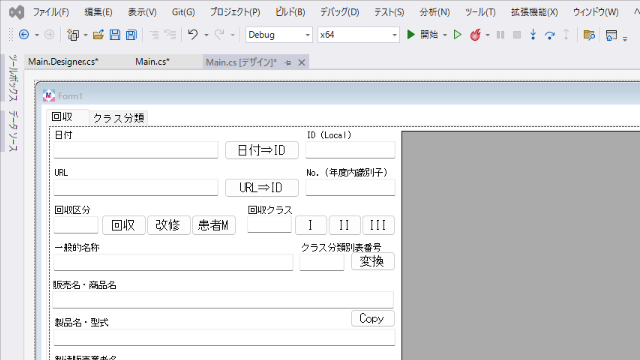
医療機器の回収等で多いのは『回収』で、概ね『改修』の2倍ほどあります。『患者モニタリング』は全体の2%も満たない程度のレアなケースです。
最も頻度が高いクラスⅡの回収を標準とすることで、作業効率が上がることを経験的に知っていたので、ボタンの並び順は『回収』が左、タブの移動で最初に当たるようにしてあります。
そして、この『回収』ボタンを押すと、自動的にクラス『Ⅱ』が入力される仕組みになっています。
| 区分 | 発生頻度 |
| 回収 | 64.0% |
| 改修 | 34.5% |
| 患者モニタリング | 1.3% |
| クラスⅠ | 0.7% |
| クラスⅡ | 91.0% |
| クラスⅢ | 8.2% |
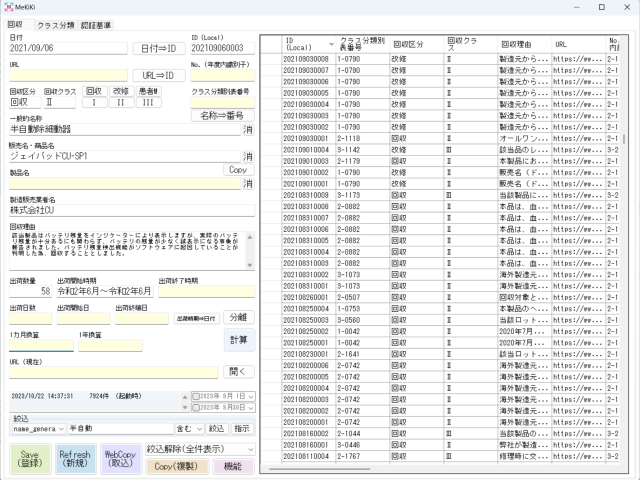
操作手順[回収情報入力]
1.システム起動
システム(EXEファイル)を起動します。
2.回収等情報取得
PMDAやMHLWの回収情報のウェブページを開きます。
ページを全選択(Ctrlキー + Aキー)し、コピー(Ctrlキー + Aキー)します。
3.貼付(ペースト)
システム側の『WebCopy』ボタンを押します。
4.URLコピー
ウェブページのURLをコピーします。
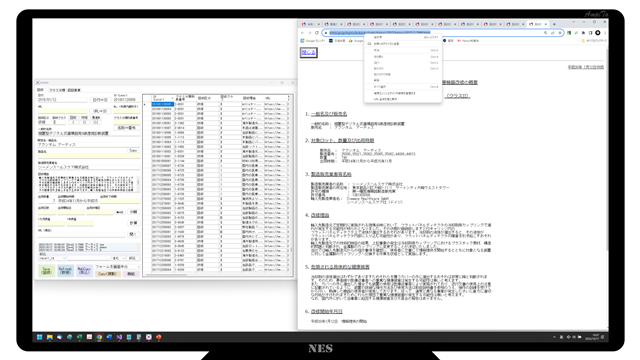
5.URL入力
システムのURL欄に貼付(ペースト)する。
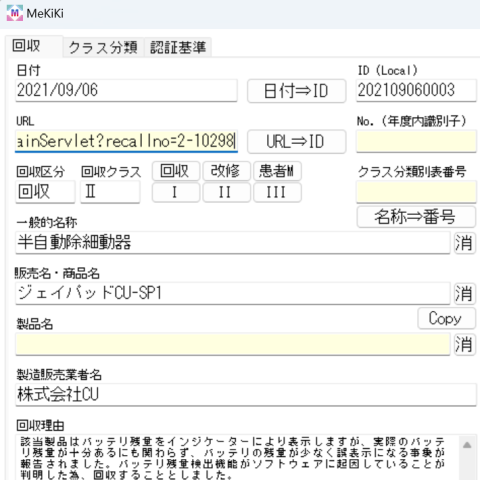
『URL⇒ID』ボタンを押してURLから回収識別子(ID)を抽出します。成功すると自動的に転記されます。
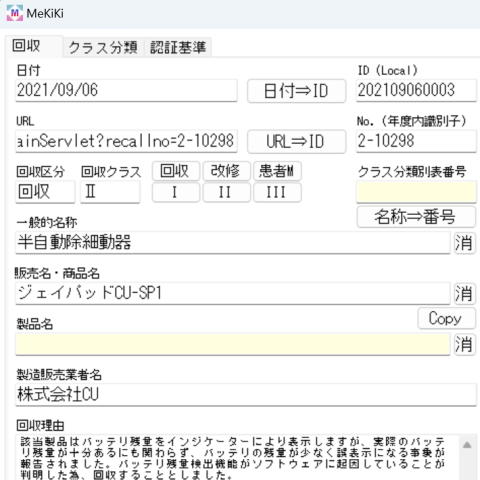
6.一般的名称
回収区分やクラスは自動的に入力されていることを想定しています。
一般的名称自体は自動入力されていることを想定しています。
『名称⇒番号』ボタンを押して識別番号を取得します。成功すると自動的に転記されます。
カーソルは販売名に移動します。
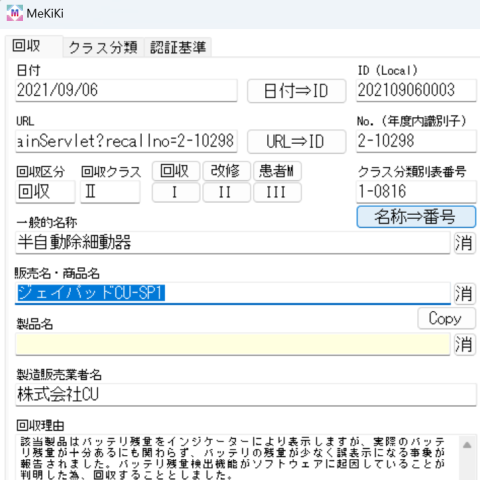
7.製品名
販売名と製品名が同じ場合は『Copy』ボタンを押すと自動的に複製されます。
異なる場合は手入力します。
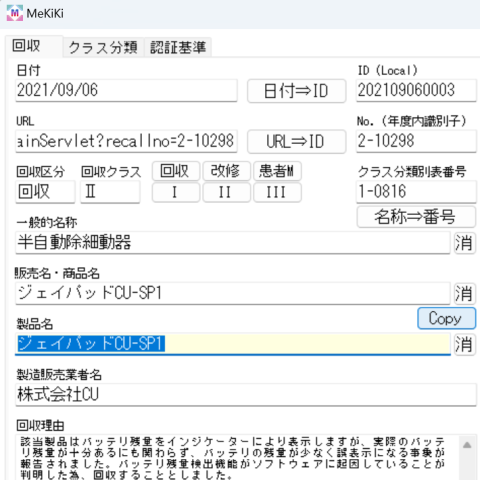
8.日付・数量
出荷数量は自動的に入力されている想定です。
出荷開始時期欄には『令和2年6月~令和2年6月』のように全期間を示す情報が入力されている場合が多いです。
『分離』ボタンを押すと自動的に出荷開始時期と出荷終了時期に分離されます。
同時に日付化できるか判定され、出荷開始日と出荷終端日が入力されます。

『計算』ボタンを押すと出荷数量、出荷開始日、出荷終端日から自動的に計算が実行され、出荷日数、1カ月換算した出荷量、1カ年換算した出荷量が算出され、自動的に記入されます。
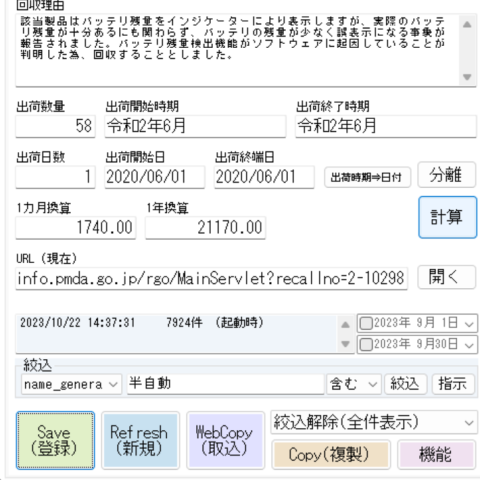
9.保存
『Save』ボタンを押して入力内容を確定します。
操作手順[CSVエクスポート]
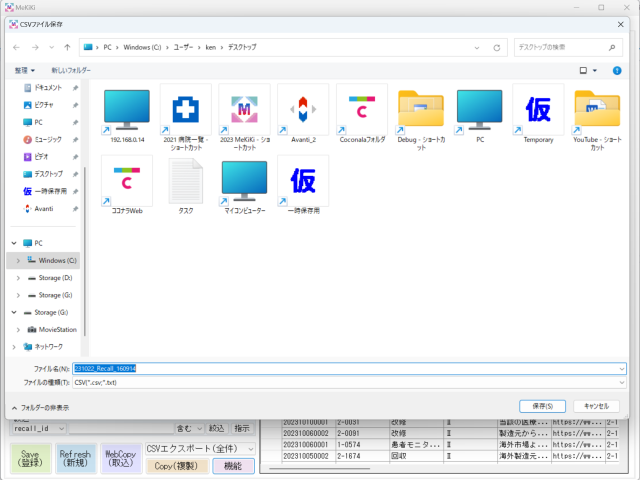
ウェブデータベースに用いるCSVファイルをエクスポートします。
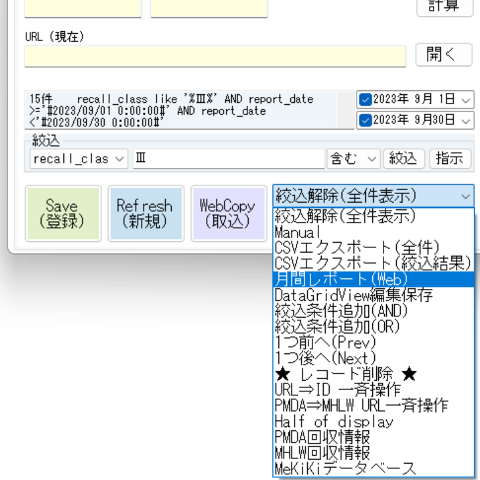
システムのドロップダウンメニューから『CSVエクスポート(全件)』を選択し、『機能』ボタンを押します。
ダイアログボックスが開き、自動的にファイル名が候補されるので、問題なければ『保存』ボタンを押します。
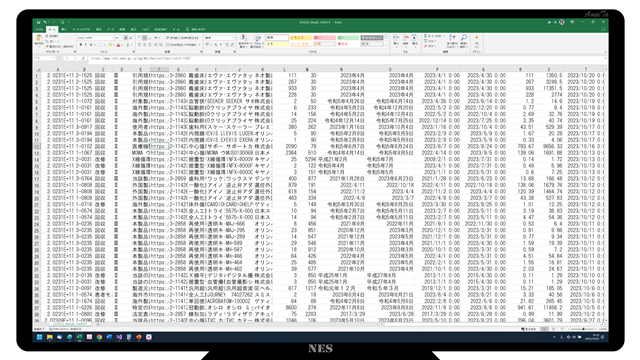
出力されたCSVファイルを開き、中身を確認します。
操作手順[ウェブデータベース]
システムで制作した回収情報をウェブで公開するためにphpMyAdminを利用しています。
所定の手順でログインします。

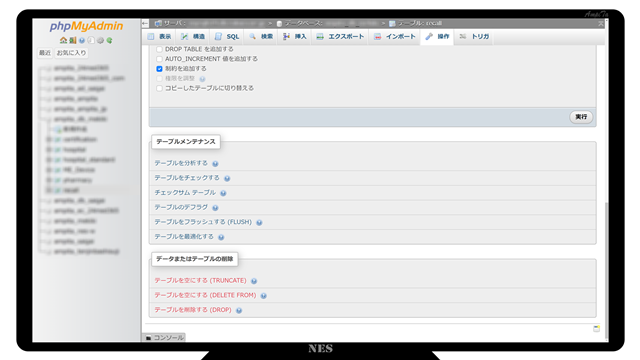
対象となるデータベースを選択し、既存のデータを削除します。
今回は『テーブルを空にする(TRUNCATE)』を使ってデータだけを削除します。
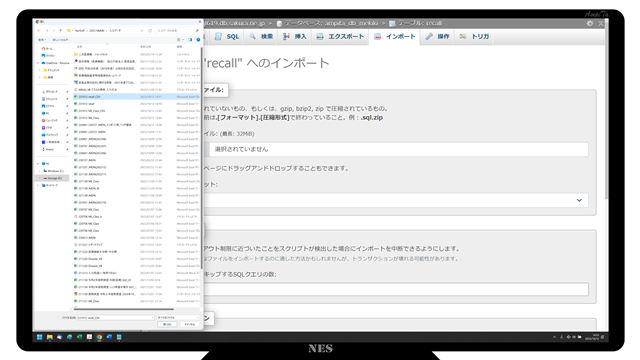
削除後、インポートタブからインポートを実行します。
ファイルの選択において、システムからエクスポートしたCSVファイルを選択します。
しばらく経つとインポートが完了するので、データベースが正しく反映されていることを確認します。
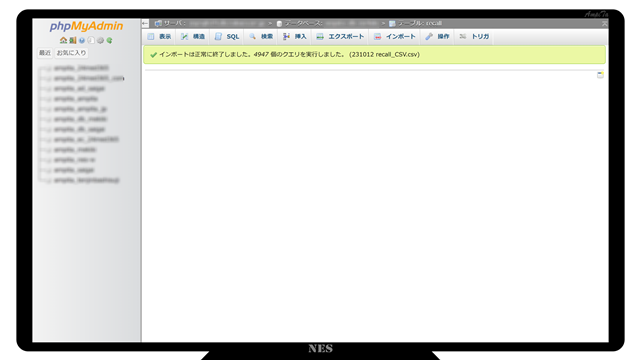
今回のシステムでインポートしたデータは MeKiKi.me で無償公開しています。
操作手順[月間レポート]
筆者は回収クラス別の月間レポートを上げているため、それを自動化するプログラムを作りました。
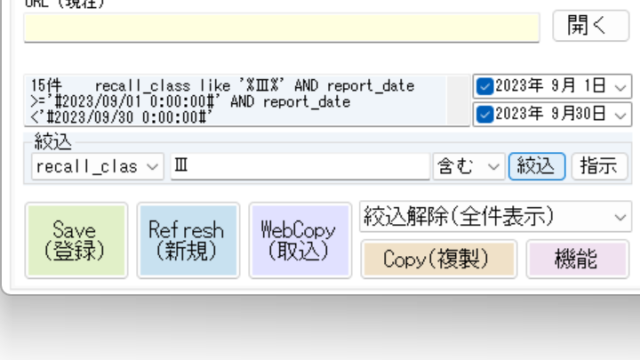
絞込項目を回収クラス(recall_class)に合わせ、対象となるクラス(Ⅰ・Ⅱ・Ⅲ)を入力します。
期間を対象月に合わせます。
上段は開始日です。図の例では『2023/09/01 00:00:00』を『>=』でくくるため、2023年9月1日を含む、それ以降の日付を取得します。
下段は終端日です。図の例では『2023/09/30 00:00:00』に1日を足した『2023/10/01 00:00:00』を『<』でくくるため、『2023/09/30 23:59:59』まで含む日付を取得します。
回収クラスと期間で絞込をしたあとで『月間レポート(Web)』を実行します。
HTMLファイル化されて出力され、標準のブラウザに表示されます。
表示されたウェブページを全選択、コピーします。
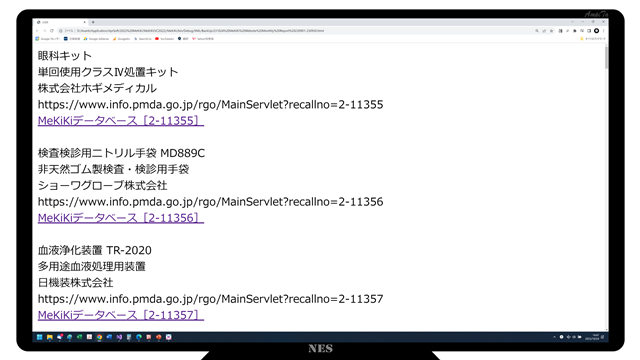
月間レポートを上げているウェブページの編集ページに貼り付け(ペースト)します。
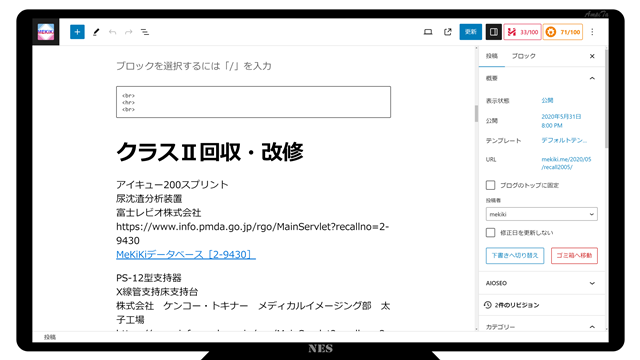
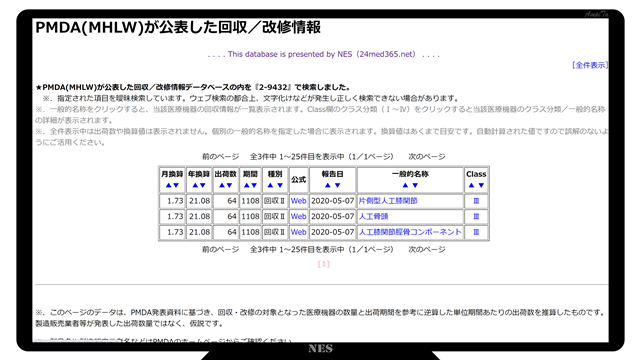
公開すると、下図のようになります。
見た目にはシステムから出力されたHTMLファイルに似ています。

個別のハイパーリンクをクリックすると、MeKiKi.meの対応したページが開くようになっています。
操作手順[ユニーク数]
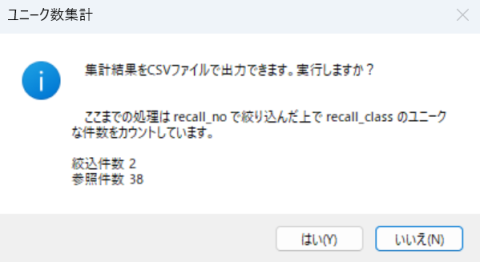
現在表示されているグリッド(DataGridView)の中から、指定した項目名のユニーク数を数えます。
機能用ドロップダウンリストから『表示中レポートユニーク数』を選択し、機能ボタンを押します。
対象となる項目をドロップダウンメニューから選択します。
回収クラス(recall_class)や回収区分(recall_reason)を想定しています。
ここで recall_id のような重複がないものを選ぶと、表示されている全件を数えるだけになります。
集計結果はCSVファイルに出力することもできます。
一般的名称などで絞った場合には件数が多いので、CSVファイルの方が見やすいです。
おわりに
今回は、以前から課題感は持っていた医療機器等の回収情報、クラス分類表、認証/承認基準のデータベースを、Microsoft AccessからVisual Studioで制作したオリジナルのシステムへ移管する作業を実施しました。
10月13日に作業を開始して、10月15日に終わったので3人日くらいでしょうか。素人が作業しているので1人日が最低賃金、およそ1万円とすると、3万円のソフトウェアということになります。
プログラミング自体は大した技を使っていないので素人でも作れましたが、そもそもの厚生労働省やPMDAが公表しているデータが処理しづらいので、そちらにノウハウがあったかもしれません。
以前書いた記事では、厚生労働省が発表している資料の中に誤記らしき文字が多いことがあるとお伝えしました。
同様に、保険医療機関の情報を公開している方法が、アナログっぽいデジタルデータであるという問題があります。
47都道府県がバラバラに公表するデータは、数年前まではファイル自体が不ぞろいでした。
全都道府県が同じ形式のXLSXファイルに統一されましたが、決められたセルに都道府県名が入っていないものが2割ほどあり、これの修正だけでも苦労しています。
ファイルのダウンロード方法も不統一で『医科』でまとめて近隣県がまっている場合もあれば、『県』でまとめられ1つの圧縮ファイルに医科、歯科、薬局が入っているものもあります。何が問題かと言うと、医科だけ処理しようと医科フォルダを作っても、九州だけは県単位でまとめているので3つのファイルを分ける作業が発生します。
今回の分でも、クラス分類表はいまだに『XLS』ファイルを使っているため、『XLSX』に変換してから次の作業に入るという面倒さがあります。
回収情報と認証基準情報はExcelなどの表計算やデータベースに係るファイルにもなっていないので、ウェブページからテキストデータとして読み、人間の手でコピペしてデータベース化しています。
公式にまとめられていない項目も存在するようで、こちらとして対処の方法に苦慮するものが多いです。
これだけの手間がかかるので、同じ事をしようという人も少なく、私たちのユニークなデータとして利用できていることがせめてものモチベーションにつながるネタだと思います。
