
AmpiTa(多用途安否確認システム)に新しいフォームを増設することになり、手順を忘れていることが多いので、次回のために備忘録を作成しています。
HTML
HTMLとは、ウェブブラウザで閲覧できるファイルです。
近年は『.php』というウェブページも増えましたが、昔は『.html』が普通でした。
古典的で普遍的な『.html』は対応している情報端末が多いため、多様な人々へ配るドキュメントとして扱いやすいと考えられます。
HTMLファイル自体をスマートフォンで見ようとすると課題がありますが、パソコンで開いた上でPDF化し、そのファイルを配ることで、より多くの情報端末に対応できることになります。
シミュレーション結果のビューア
今回はシミュレーションするシステムを開発している中での備忘録なので、題材はシミュレーションです。
このシミュレーションでわかるデータは、医療的ケア児など在宅医療を受ける患家で役立てるので、EXEファイルで結果を閲覧できても役に立ちづらいです。
そこで、ブラウザで簡単に閲覧できるシステムの開発に注力しました。
最後に『Diagnostics.Process.Start』で制作したファイルを既定のプログラムで呼び出す処理を入れます。一般的にはブラウザが開くと思います。
HTMLファイルの作成は『.txt』や『.csv』などのファイルを制作する場合と同じです。『StreamWriter』で指定した変数にテキストデータを格納していくことになります。
注意点としては、HTMLタグを使わなければならない点です。
HTMLでは『<body>』から『</body>』の間に本文を入力するので、そのように作ります。
最後に『StreamWriter』の『Close』の指示を忘れずに入れれば、指定したフォルダにHTMLファイルが保存されます。
StreamWriter file_HTML_write = new StreamWriter(@str_FN + "\\" + "index.html", false, Encoding.UTF8);
file_HTML_write.WriteLine("<!DOCTYPE html>");
file_HTML_write.WriteLine("<body>");
(本文)
file_HTML_write.WriteLine("</body>");
file_HTML_write.WriteLine("</html>");
file_HTML_write.Close();どのような内容にするかは自由なので、HTMLタグを少し理解できれば簡単に作れると思います。
今回は結果を一覧表にまとめて、そこにコメントを付けるようなHTMLファイルを作っています。
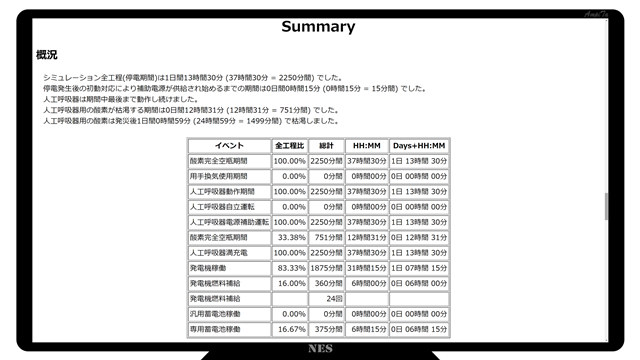
EXEファイルでは画面端に小さな字で書かれた情報を、ブラウザで見やすくしています。
また、ブラウザでは印刷にも対応し、PDFファイル化も容易にできるので、EXEファイルで管理するよりユーザーフレンドリーだと思います。
印刷時の改ページ
HTMLファイルをウェブブラウザで閲覧する際には、シームレスであることが画面スクロールしていて見やすい画面になりますが、印刷するとタイトルとコンテンツが別ページになってしまったりします。
そこで、印刷時に見やすいように区切るタグを埋め込んでいます。ChromeやEdgeなどでは印刷機能を使ってPDFファイルを出力できるため、PDF化して配る際にも役立つページ区切りです。
『div』タグの『style』タグで『page-break-after: always;』と指示することで、その位置にページを区切る指示が入ります。ブラウザで表示しているだけでは存在に気づきません。
file_HTML_write.WriteLine("<div style=\"page-break-after: always;\"></div>");今回のシミュレーターの画面を印刷すると、下図のように分割されて印刷されます。PDFファイルも同様です。
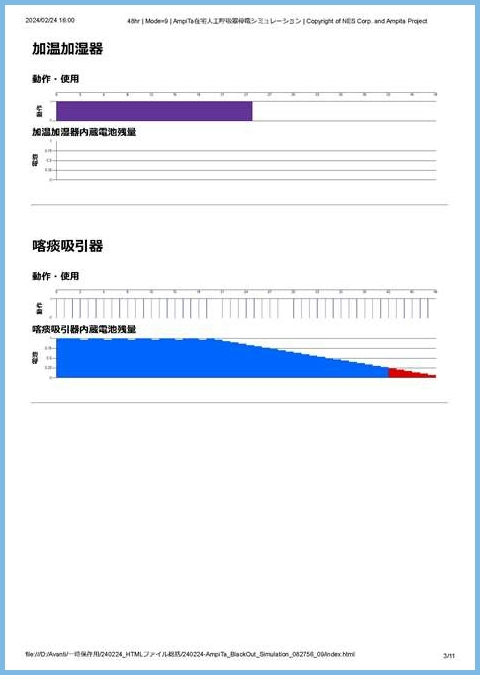
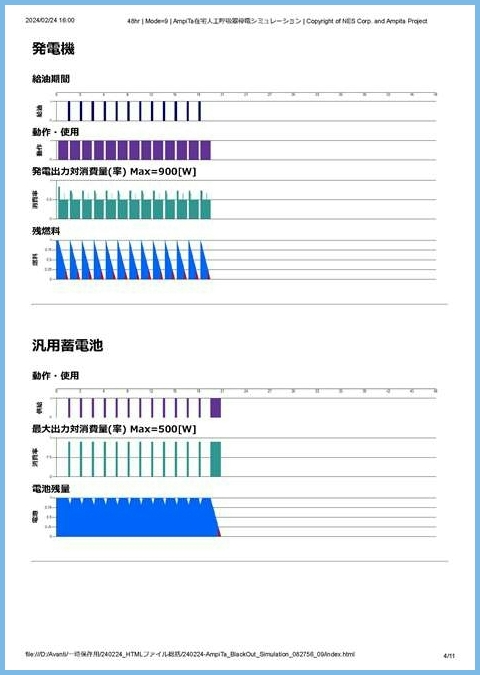
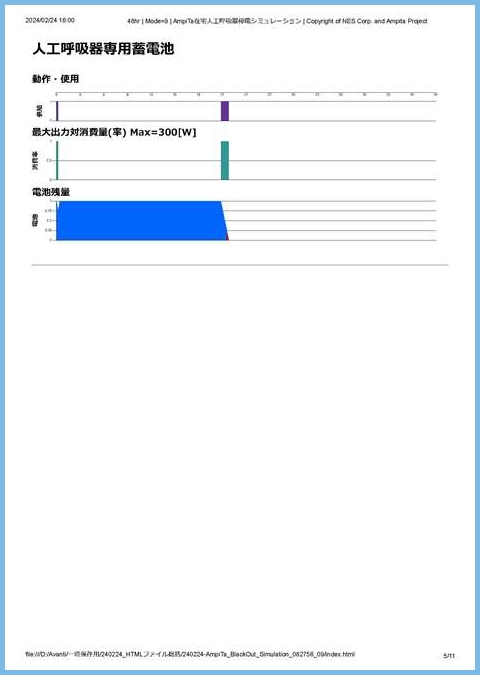

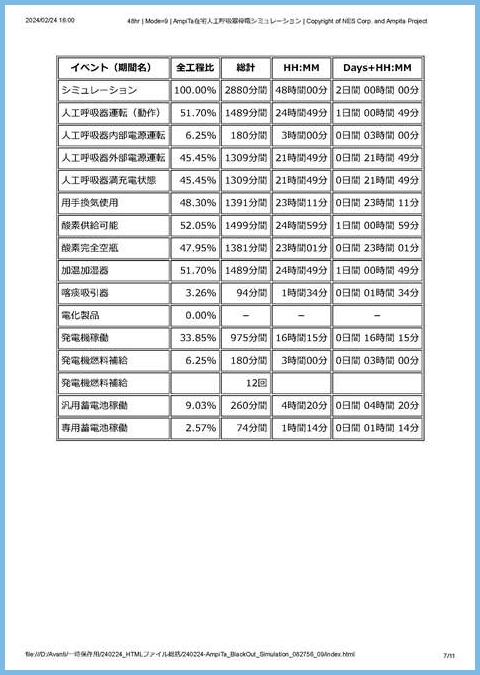



フォルダ内HTMLファイル参照ウェブページ
条件による違いを比較するために、複数ファイルを一斉に出力する機能を開発しました。
条件別ファイルは比較をしたいのですが、別フォルダとして出力されるためまとまりません。
そこで、まとめるためのHTMLファイルを作成しました。
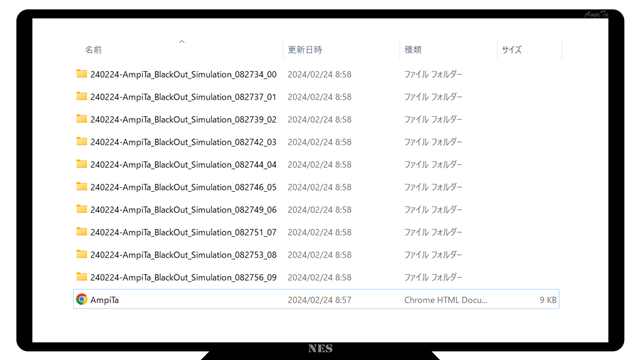
1つのウェブページ(HTMLファイル)に、同フォルダ内のすべての結果をまとめて表示し、かつ、それらの個別ファイルにアクセスする機能を備えました。
まずは冒頭で複数フォルダをまとめているフォルダを指定します。指定されたフォルダを『DirectroyInfo』読込んで取り扱います。
指定したフォルダ内に存在するフォルダを1件ずつ確認し、その中に『index.html』が存在するファイルだけを残すというプログラムにします。
FolderBrowserDialog selectFolder = new FolderBrowserDialog();
if (selectFolder.ShowDialog(this) == DialogResult.OK) { } else{ return; }
string str_Folder_Name = selectFolder.SelectedPath;
string[] str_Exists_Files = new string[0] { };
System.IO.DirectoryInfo diDirectoryInformation = new System.IO.DirectoryInfo(@str_Folder_Name);
System.IO.DirectoryInfo[] di_DirectoryInformation_Child = diDirectoryInformation.GetDirectories();
foreach (System.IO.DirectoryInfo Open_HTML_Directory in di_DirectoryInformation_Child)
{
(別記)
}実行すると、このような感じです。
フォルダ内全検索(foreach)の構文内で『別記』とした部分には下記コードが入ります。
まず『if』文でフォルダ内に『index.html』というファイルが存在するのかを『System.IO.File.Exists』で確認します。
結果が『true』の場合、String変数の『str_Exists_Files』に『Array.Resize』を使ってデータを1つ追加します。データ番号は『str_Exists_Files.Length + 1』です。すなわち『str_Exists_Files.Length』で得られる格納データ数に1つ追加という指示です。
新たに設けたデータ枠を『str_Exists_Files[str_Exists_Files.Length – 1]』で指定し、そこに if 文で true となったフォルダ名を格納します。
string str_Check = Open_HTML_Directory.Name;
if (System.IO.File.Exists(str_Folder_Name + "\\" + str_Check + "\\" + "index.html"))
{
Array.Resize(ref str_Exists_Files, str_Exists_Files.Length + 1);
str_Exists_Files[str_Exists_Files.Length - 1] = str_Check;
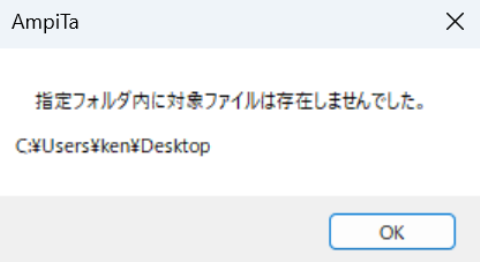
} 『foreach』を抜けた直後に、データがあったか確認します。
if (str_Exists_Files.Length < 1)
{
MessageBox.Show("指定フォルダ内に対象ファイルは存在しませんでした。", "AmpiTa");
return;
}
実行すると、このような感じです。
有効なフォルダが1つでも存在すれば、下記コードに移ります。
テキストファイルなどを制作する際に用いる『StreamWriter』を利用してHTMLファイルを制作します。
ファイルの保存先は、今回探索したフォルダです。ファイル名は『AmpiTa.html』としています。
『WriteLine』で一行書き込みします。
最初にHTMLファイルのお作法的な文言を書き込み、そのあとで本題部分を『for』で書き込みます。
『for』文は『str_Exists_Files.Length』に至るまで循環するように指示ます。
見出しは『h2』サイズで、個別フォルダ名を示します。
個別フォルダには概要を示す2枚の画像があるので、それを表組みして左右に並べます。『table』から始まる構文が表組み、『tr』で新しい行を作り、『td』で新しいセルを作ります。
『img src』で画像を呼出し、『href』でリンクを付けます。』
最後に『Diagnostics.Process.Start』で制作したファイルを既定のプログラムで呼び出す処理を入れます。一般的にはブラウザが開くと思います。
StreamWriter file_HTML_write = new StreamWriter(@str_Folder_Name + "\\" + "AmpiTa.html", false, Encoding.UTF8);
file_HTML_write.WriteLine("<!DOCTYPE html>");
file_HTML_write.WriteLine("<body>");
for (intRound = 0; intRound < str_Exists_Files.Length; intRound++)
{
file_HTML_write.WriteLine(
"<h2>" + "\r\n" +
"<a href=\"" + str_Exists_Files[intRound] + "/index.html" + "\" target=\"_blank\">" + str_Exists_Files[intRound] +
"</a>" + "\r\n" + "</h2>" + "\r\n" + "\r\n");
file_HTML_write.WriteLine(
"<table border='0' cellpadding='5' align=\"center\" width=\"100%\">" + "\r\n" + "<tr>" + "\r\n" + "\r\n" +
"<td align=\"center\">" + "\r\n" +
"<a href=\"" + str_Exists_Files[intRound] + "/index.html" + "\" target=\"_blank\">" + "\r\n" +
"<img src=\"" + "./" + str_Exists_Files[intRound] + "/" + "img_AmpiTa" + "/" + str_Exists_Files[intRound] + "_Setup" + ".png" + "\" alt=\"AmpiTa\" title=\"AmpiTa\" width=\"100%\">" + "\r\n" +
"</a>" + "</td>" + "\r\n" + "\r\n" +
"<td align=\"center\">" + "\r\n" +
"<a href=\"" + str_Exists_Files[intRound] + "/index.html" + "\" target=\"_blank\">" + "\r\n" +
"<img src=\"" + "./" + str_Exists_Files[intRound] + "/" + "img_AmpiTa" + "/" + str_Exists_Files[intRound] + "_Draw" + ".png" + "\" alt=\"AmpiTa\" title=\"AmpiTa\" width=\"100%\">" + "\r\n" +
"</a>" + "</td>" + "\r\n" + "\r\n" +
"</tr>" + "\r\n" + "</table>" + "\r\n" + "<br>" + "\r\n" + "\r\n");
}
file_HTML_write.WriteLine("</body>");
file_HTML_write.WriteLine("</html>");
file_HTML_write.Close();
System.Diagnostics.Process.Start(@str_Folder_Name + "\\" + "AmpiTa.html");
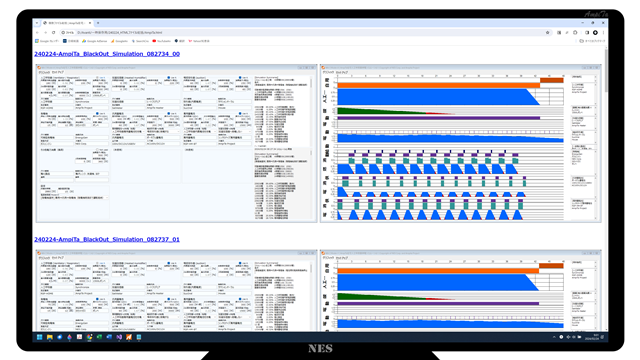
結果は下図のようになります。
見出しがフォルダ名の文字列で、そこにリンクがかかっているので青色文字、下線付きとなっています。
その直下には2枚の画像、これにもリンクが張られています。
リンクを開くと下図のような結果の個別ファイルがブラウザで閲覧できます。
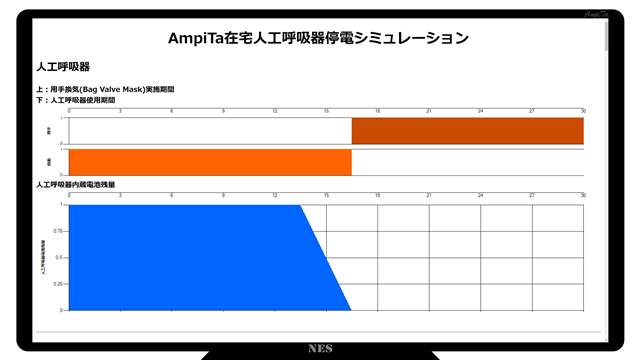
下方にスクロールしていくと、活字のサマリーが見れるようになっています。
隠しキー
HTMLタグには隠しキーというか、表示や動作に影響しないコメントを残す『コメントアウト』という機能があります。
『<!– 』からはじまり『–>』で終わります。
<!--
このHTMLファイルは
西門義一
様のために制作しました。
-->
<!DOCTYPE html>
<html lang="ja">
<head>上記コードの冒頭には制作者側が使うコメントが記載されています。
3行目は個人名(ここでは架空の人物)が入っていますが、別のプログラムでこの部分を抜き出して利用することができます。
下記コードでは『TextFieldParser』でHTMLファイルをテキストファイルのような形で読込んでいます。手作業で言えばWindowsの『メモ帳』を使っている状態です。エンコーディングは『UTF-8』でも『Shift_JIS』でも機能しました。
『TextFieldType』は『Delimited』としています。固定長の場合は『FixedWidth』です。
『SetDelimiters』でカンマ区切りの文字列であることを指示しています。
『txfParser_HTML.ReadFields()』で変数『tr_HTML_OneLine』に一行丸ごと格納します。
これが3行連続するのは、1行目、2行目、3行目と読込むためです。1行目と2行目は使わず、3行目で処理に入ります。
『List_PersonalData』に『str_HTML_OneLine』のデータをリストとして格納します。
『foreach』で『str_HTML_OneLine』からカンマ1つ分ずつのデータを表示していきます。
TextFieldParser txfParser_HTML = new TextFieldParser(@str_FullPath, Encoding.GetEncoding("utf-8"));
txfParser_HTML.TextFieldType = FieldType.Delimited;
txfParser_HTML.SetDelimiters(",");
string[] str_HTML_OneLine = txfParser_HTML.ReadFields();
str_HTML_OneLine = txfParser_HTML.ReadFields();
str_HTML_OneLine = txfParser_HTML.ReadFields();
List<string> List_PersonalData = new List<string>();
List_PersonalData.AddRange(str_HTML_OneLine);
foreach (string strList in List_PersonalData)
{
Console.WriteLine(strList);
}
txfParser_HTML.Close();おわりに
WordPressを使い始めてからは、ごく一部にだけHTMLタグを打ち込んで指示を出していますが、ほぼ自動化されたのでウェブページ全体をHTMLで構築する方法を忘れかけていました。
今後は、忘れていても自動的に生成できますので、このシミュレーターに関しては課題は無くなりました。
関連記事
- [C#備忘録]XML・DataTable絞込・指示 | AmpiTa Project
- [C#備忘録]複数のNumericUpDownから最適値を探す | AmpiTa Project
- [備忘録]PHP7.4⇒8.0 アップ … ウェブページのデータベース接続構文を変更 | AmpiTa Project
- [C#備忘録]高DPIへの対応(目標未達) | AmpiTa Project
- [C#備忘録]HTMLファイルでレポート | AmpiTa Project
- [C#備忘録]画像ファイル出力 | AmpiTa Project
- [C#備忘録]Excelファイルをインポート | AmpiTa Project
- [C#備忘録]XMLファイルで集計 | AmpiTa Project
- [C#備忘録]定型化のためのGroupBox利用とTextBox配置 | AmpiTa Project
- [C#備忘録]新規フォーム追加/Size/Location/Position | AmpiTa Project